有很多小伙伴问过我零基础要怎么入门机器学习或者人工智能,今天来提炼一下,方便志同道合的朋友们参考。
什么是机器学习?
机器学习的核心思想是创造一种普适的算法,它能从数据中挖掘出有趣的东西,而不需要针对某个问题去写代码。你需要做的只是把数据“投喂”给普适算法,然后它会在数据上建立自己的逻辑。
比如说有一种算法,叫分类算法,它可以把数据分到不同的组别当中。一个识别手写数字的分类算法,也可以用作判断垃圾邮件,而无需修改一行代码。算法是同一个算法,只是输入了不同的训练数据,便有了不同的分类逻辑。
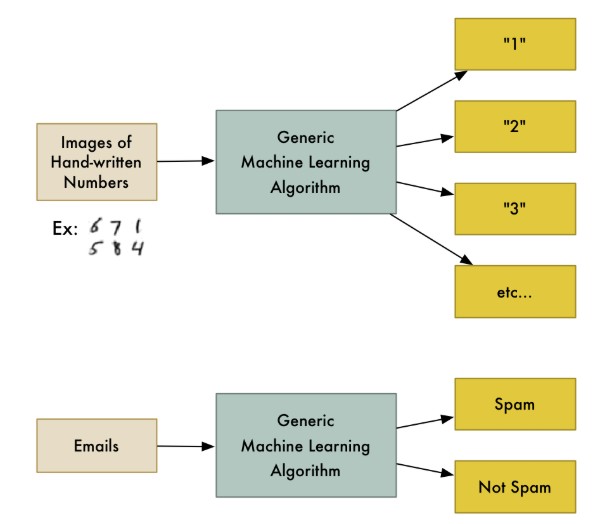
机器学习的核心是“使用算法解析数据,从中学习,然后对世界上的某件事情做出决定或预测”。这意味着,与其显式地编写程序来执行某些任务,不如教计算机如何开发一个算法来完成任务。有三种主要类型的机器学习:监督学习、非监督学习和强化学习,所有这些都有其特定的优点和缺点。
机器学习常用术语
机器学习领域有着许多非常基本的术语,这些术语在外人听来可能相当高深莫测。它们事实上也可能拥有非常复杂的数学背景,但需要知道:它们往往也拥有着相对浅显平凡的直观理解(上一小节的假设空间和泛化能力就是两个例子)。本小节会对这些常用的基本术语进行说明与解释,它们背后的数学理论会有所阐述,但不会涉及过于本质的东西。
正如前文反复强调的,数据在机器学习中发挥着不可或缺的作用;而用于描述数据的术语有好几个,需要被牢牢记住的如下。
“数据集”(Data Set),就是数据的集合的意思。其中,每一条单独的数据被称为“样本”(Sample)。若没有进行特殊说明,本书都会假设数据集中样本之间在各种意义下相互独立。事实上,除了某些特殊的模型(如隐马尔可夫模型和条件随机场),该假设在大多数场景下都是相当合理的。
对于每个样本,它通常具有一些“属性”(Attribute)或者说“特征”(Feature),特征所具体取的值就被称为“特征值”(Feature Value)。
特征和样本所张成的空间被称为“特征空间”(Feature Space)和“样本空间”(Sample Space),可以把它们简单地理解为特征和样本“可能存在的空间”。
相对应的,我们有“标签空间”(Label Space),它描述了模型的输出“可能存在的空间”;当模型是分类器时,我们通常会称之为“类别空间”。
其中、数据集又可以分为以下三类:
训练集(Training Set);顾名思义,它是总的数据集中用来训练我们模型的部分。虽说将所有数据集都拿来当作训练集也无不可,不过为了提高及合理评估模型的泛化能力,我们通常只会取数据集中的一部分来当训练集。
测试集(Test Set);顾名思义,它是用来测试、评估模型泛化能力的部分。测试集不会用在模型的训练部分,换句话说,测试集相对于模型而言是“未知”的,所以拿它来评估模型的泛化能力是相当合理的。
交叉验证集(Cross-Validation Set,CV Set);这是比较特殊的一部分数据,它是用来调整模型具体参数的。